Видео с ютуба Mlx-Powered Ollama
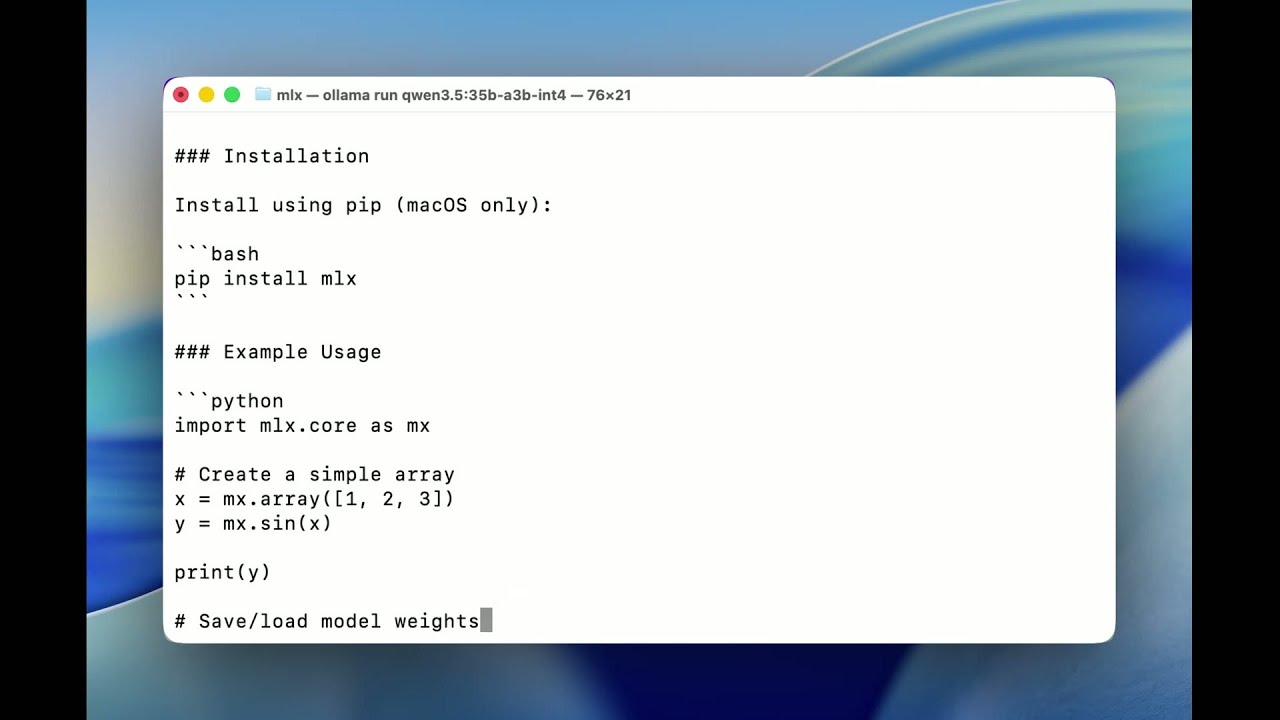
Ollama 0.19 MLX on Apple Silicon — 2x Faster, Fully Local

Ollama перешла на Apple MLX — вот почему всё работает быстрее.

Apple MLX vs llama.cpp: Which is Really Faster? (4 Runtimes - Ollama Included)

Ollama powered by MLX on Apple Silicon

Ollama на базе MLX на M5 Max: 128 ГБ ОЗУ для невероятно высоких локальных уровней LLM! 🤯

Разница в точности Qwen3-VL на Ollama и MLX

Ollama vs MLX Inference Speed on Mac Mini M4 Pro 64GB

Ollama Mac MLX уже здесь — в 2 раза быстрее по скорости передачи данных для Apple Silicon Mac/Mac...

Fine Tune a model with MLX for Ollama

Your local LLM is 10x slower than it should be

Local AI just leveled up... Llama.cpp vs Ollama
The Ollama MLX Trap: Why Your Mac LLM Setup Is Leaving 2x Speed on the Table | #NEWIT

Osaurus is the Super Cute Alternative to Ollama that Runs MLX

Fine-tune & Chat with LLMs Locally: MLX + Ollama + Open WebUI Tutorial (Apple Silicon) 🚀

Ollama на Mac стала в 2 раза быстрее (вот как это сделать)

Ollama vs LM Studio: Which Local AI Tool Wins in 2026?